
- Dette arrangement har allerede funnet sted.
Julemøte i Trondheim: Menneske-tolkbar maskinlæring med blikk for fysikk
Årets julemøte med faglig innslag og tradisjonell rakfiskbuffét
Menneske-tolkbar maskinlæring med blikk for fysikk.
Finn rytmene og harmoniene i tekniske stordata – uten matte-angst og black-box fordumming
Sett av datoen, det er begrenset plass! Ledsagere er velkomne.
Billetter er lagt ut på Hoopla.

Harald Martens, bio-kjemometriker. harald.martens@ntnu.no
Prof. emerit. innen Stordata kybernetikk, Inst. teknisk kybernetikk NTNU. Senior-konsulent, Idletechs AS, Trondheim
Dette foredraget handler om hvordan overveldende strømmer av tekniske måledata kan tolkes av mennesker, omtrent som vi lytter til musikk.
Klimaet, økonomien og verdensfreden krever at vi gjør raske, men sindige endringer, ikke minst ved hjelp av teknologi. For å få det til, må vi forstå virkeligheten bedre. Det krever flere og bedre måledata, og enda bedre tolkning og bruk av disse.
Nye, kontinuerlige avbildende måleteknikker, for eksempel mangekanals hyperspektrale eller termiske videokameraer, gir tekniske stordata så det holder. Riktig brukt, har disse vist seg å ha stort informasjons-potensiale, både innen landbruk, medisin, miljøovervåking, prosessindustri, forsvar og romfart.
Men hvordan tolke og bruke moderne tekniske stordata på en enkel og robust måte? Strømmen av rådata blir overveldende, og både data-tolkningen, lagringen og den praktiske bruken krever derfor en eller annen form for matematisk data-forenkling og statistisk validering.
Vi mennesker deler oss ofte – grovt sett – i to grupper – eksaktikere og omtrentikere. Er man eksaktiker, kan man trives i Matematikkens Hus – der man liker konsise matematiske formler og bevis. På jobb kan man sette opp en kausal modell – et sett med eksakte matematiske ligninger som beskriver hva vi tror det er som skaper variasjon i våre målinger. Så kan vi tilpasse modellen til malstrømmen av faktiske måledata – med varierende hell. Mye god vitenskap er kommet ut av slik hypotetisk-deduktiv modellerings-tankegang. Men hvordan modellere variasjonsmønstre som vi kan se i dataene, men enda ikke forstår? Hvordan modellere det ukjente med differensial-ligninger?
Er man omtrentiker (som foredragsholderen, opprinnelig), trives man best i Huset for Alt Annet Enn Matematikk – kanskje med gammel matte-angst – eller kanskje man bare er litt lat. Da kan man fristes til å «bruke maskinlæring», f.eks. til klassifikasjon og prediksjon, – samle Big Data og trykke på en AI-knapp – så slipper man jo å tenke selv! Men den går ikke. Kunstig Intelligens-feltet har utviklet fantastiske datadrevne, induktive modelleringsverktøy, med stort potensiale til å endre vårt samfunn – på godt og vondt. Men fleksibiliteten og kompleksiteten i disse maskinlæringsmodellene gjør at de krever enorme mengder av velvalgte treningsdata, samt stor menneskelig system-innsikt, for å gi pålitelige løsninger. Å trene opp et dyplærings-nevralnett koster en god del strøm. Men det koster mer å fremskaffe alle treningsdataene. Og aller mest å senere måtte forsvare seg i retten når ens system har gått ufattelig galt.
Foredraget beskriver en tredje vei, som bygger to-vegs bro over Matte-Gapet i samfunnet:
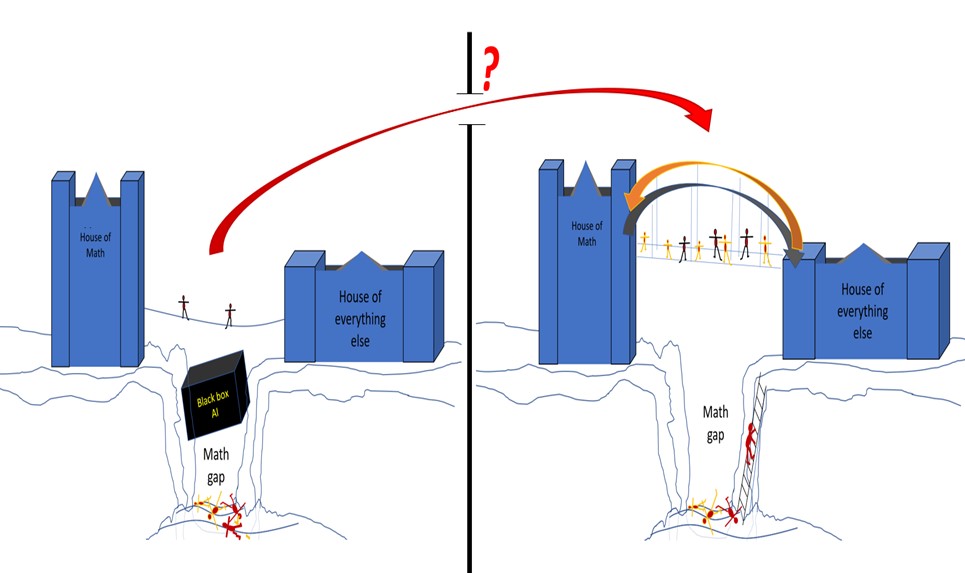
«Myk multivariat datamodellering» kan bygge bro mellom eksaktikerne og omtrentikerne blant oss.
Metodikken funker ikke for alle slags stordata. Men den har vist seg nyttig for mange typer teknisk-naturvitenskapelige målinger, i pragmatiske fagfelt som stordata kybernetikk og kjemometri – spesielt innenfor multivariat instrument-kalibrering. Og det med god grunn:
For selv om tekniske måledata påvirkes av flere ulike variasjonsårsaker, er det resulterende antallet relevante hoved-variasjonsmønstre i en gitt sammenheng som oftest relativt beskjedent – f.eks. 10 eller mindre. Og dersom man bruker moderne mange-kanals instrumenter – måler mange bilde-piksler, mange tidspunkter, mange bølgelengder lys og / eller mange kjemiske stoffer samtidig, kan den overveldende datastrømmen gjøres selv-modellerende! Man kan nemlig anse et moderne måleinstrument som et mange-strengs musikkinstrument, og slappe av mens man lytter til lyd og ulyd i signal-musikken: Man bruker et dataprogram som registrerer harmonier og rytmer – dvs dataenes samvariasjons- hovedmønstre (eigenvektorer), og som reagerer raskt når det kommer unormale disharmonier og arytmier. Slik slipper man naturlovene tett innpå seg.
Eksaktikerne blant oss vil da finne en velutviklet underliggende approksimasjonsteori, og mange akademiske og kommersielle anvendelser for dette. Omtrentikerne vil nok like den åpne musikalske arkitekturen, som lar brukerne nyte synet av både forventede og uventede samvariasjonsmønstre. Den relativt lave dimensjonaliteten i de resulterende datamodellene gjør det nemlig lett å tolke resultatene grafisk – altså ingen black box. Den underliggende, enklest-mulige, lokalt lineære underroms-modelleringen bygger stort sett kun på ungdomsskole-algebra:
A ~ B X C + D
Med andre ord: Ingen grunn til panikk.
Referanser:
H. Martens og T. Pedersen: Maskinlæring med blikk for fysikk. Teknisk Ukeblad 5. 6. 2023 / 530650.
H. Martens: Causality, machine learning and human insight. Analytica Chimica Acta 9. 8. 2023 / 341585